r/accelerate • u/obvithrowaway34434 • 5m ago
AI These are the actual AI data center CO2 emission compared to other industries
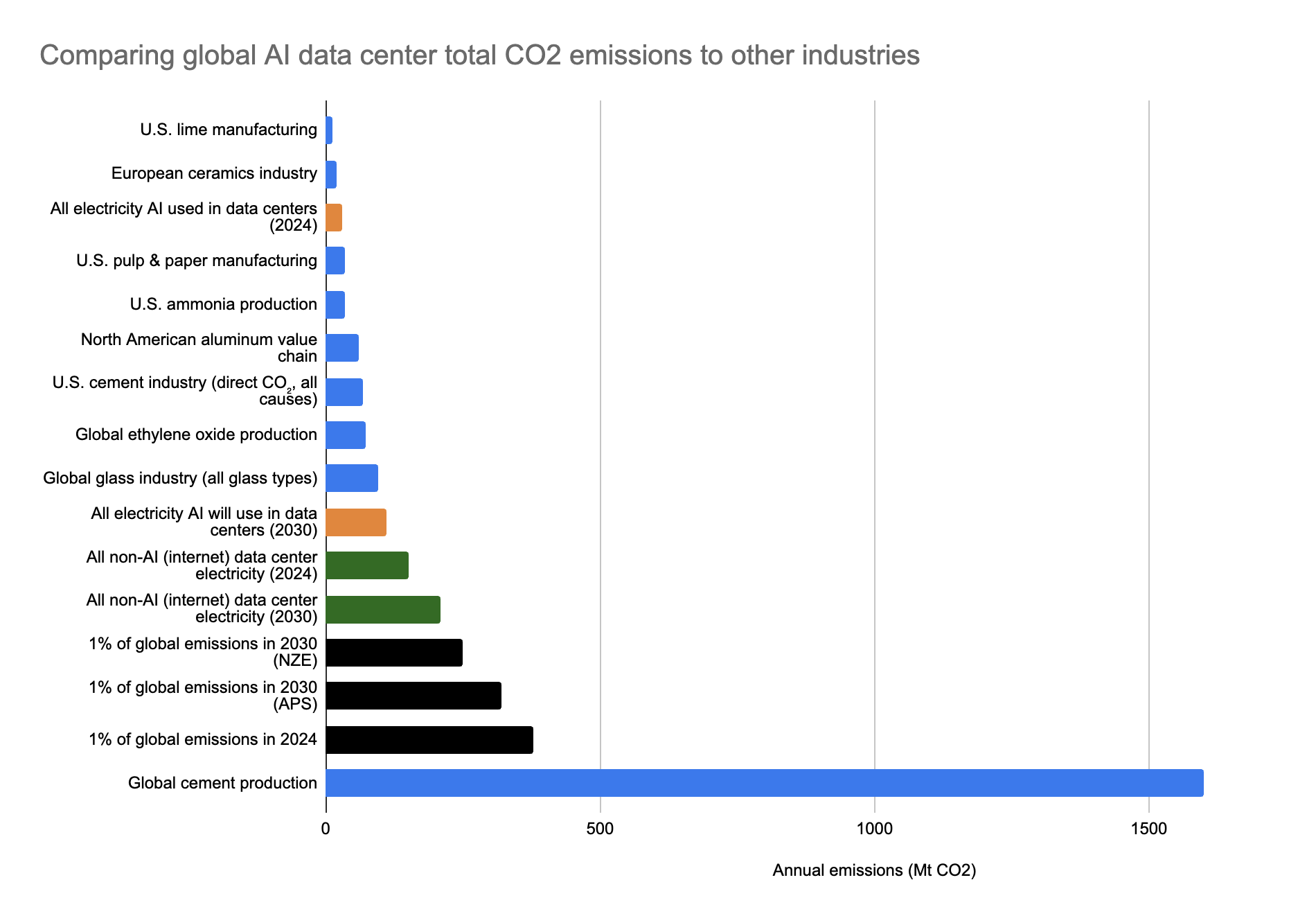{kind=link}
•
Upvotes
r/accelerate • u/obvithrowaway34434 • 5m ago
r/accelerate • u/The_Sad_Professor • 2h ago
r/accelerate • u/Ok-Possibility-5586 • 2h ago
https://www.nbcnews.com/tech/tech-news/humans-hired-to-fix-ai-slop-rcna225969
Full summary:
AI was expected to replace creative workers, but instead it has created a new category of "AI cleanup" jobs where freelancers are hired to fix the mistakes and shortcomings of AI-generated content. From graphic designers correcting malformed logos to writers humanizing robotic text to developers debugging faulty AI code, creative professionals are finding work in addressing AI's limitations. Despite AI's growing presence, the market increasingly values the human touch, creativity, and quality that AI cannot fully replicate, suggesting that human workers remain essential for delivering polished, context-appropriate content.
TLDR summary;
This piece is framed in a particular way "fixing slop" but regardless, this is where the jobs are coming from with respect to AI - humans are the finishers.
r/accelerate • u/dental_danylle • 9h ago
Source:
r/accelerate • u/Illustrious-Lime-863 • 10h ago
r/accelerate • u/Ruykiru • 15h ago
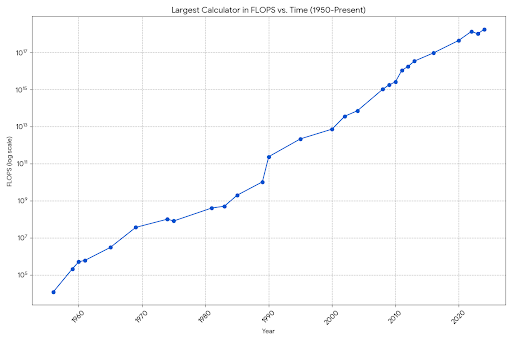
This is absolutely mind blowing. My mind cannot process that we went from copper tools to this in a couple thousand years. Hell, transistors are only like 75 years old.
r/accelerate • u/Mindless-Cream9580 • 18h ago
To estimate AGI, I postulated that at AGI, we have: LLM size = Nb of neurons * Connections per neuron
Nb of human neurons = 100 billions Connections per neuron = 1000 So that: Nb of neurons * Connections per neuron = 100 trillions
LLM current size = 1 trillion
So in how much time will we reach a LLM with 100 trillion? Let's look at super calculators history, factor x100 every ten years
So LLM (2035) = 100 trillion And AGI in 2035
r/accelerate • u/stealthispost • 21h ago
r/accelerate • u/Best_Cup_8326 • 21h ago
The problem, however, isn't the size of the UBI check, but rather whether that money retains any of it's value. $10k/mo is worthless if a gallon of milk costs $10k.
r/accelerate • u/toggler_H • 1d ago
When will we see safe, scalable technologies that can truly boost human intelligence memory, reasoning, learning speed, creativity far beyond today’s limits?
Some possible paths I've considered:
Questions for discussion:
r/accelerate • u/matttzb • 1d ago
Reaching Longevity Escape Velocity relatively soon is contingent on Artificial Super Intelligence existing first. Ultimately when someone gives a date for when LEV is going to be achieved (and they are aware of the wider metaphenonenon of accelerating returns within technology as a whole, as well as AI) they likely shouldn't be placing the advent of LEV to far after the emergence of super-intelligence. So, when do you guys think something approximating super-intelligence will be achieved? I personally think that something approximating this will arrive in 2029-2030, at the earliest. I don't think it will arrive later than 2035, so I think LEV could be as soon as 2034-2040. What do you guys think? What's your reasoning?
r/accelerate • u/Special_Switch_9524 • 1d ago
r/accelerate • u/44th--Hokage • 1d ago
My dream for FDVR is essentially super advanced Genie + VR + IRL haptics. History can be revisited, or better yet, history can be changed by your actions...
What historical events would you re-live in FDVR?
r/accelerate • u/stealthispost • 2d ago
r/accelerate • u/stealthispost • 2d ago
r/accelerate • u/stealthispost • 2d ago
r/accelerate • u/FudgeyleFirst • 2d ago
Guys did u see meta’s deepconf it got 99.99% on aime by using confidence factors for gpt oss
r/accelerate • u/Maleficent-Carob7960 • 2d ago
The question isn’t if. It’s how fast.
r/accelerate • u/kanadabulbulu • 2d ago
https://copilot.microsoft.com/labs/audio-expression
Pick Moss for voice and for style shyness, sadness or joy , prompt "Hi, I'm Samantha, your new friend, im here to support you " and hit generate ... let me know if its her :)
r/accelerate • u/Mysterious-Display90 • 2d ago
r/accelerate • u/floopa_gigachad • 3d ago
It will be available at the end of this year, iirc
GPT-5 is optimised for ~1B users, so it is not the most powerful model technically possible. Also remember there is IMO gold model behind the scenes. Considering these factors and ongoing exponential trend, how powerful could be such costly model in November-Desember 2025? I think it will be as satisfying as o3 in January
r/accelerate • u/OneSafe8149 • 3d ago
I've been building something recently and wanted to get some honest feedback.
The idea: • You give an Al ongoing context about what you're working on, building, or thinking about. • Instead of having to re-explain everything each time, the Al already knows the background and can respond in a more useful way. • You can also share that same context with other people, so when you're collaborating, they don't just see the end result, but the thought process and progress behind it.
So it becomes like a portable memory layer: Al remembers your projects, and humans can plug into that same memory without long explanations.
Kind of like moving from one-off conversations → to a shared workspace of thoughts + reasoning.
• Would you actually use this? • If yes, where would it be most useful (personal productivity, team collaboration, creative projects, etc.)? • If no, what's the biggest blocker?
r/accelerate • u/dental_danylle • 3d ago
Tech shifts often feel gradual, but then suddenly something just vanishes. Fax machines, landlines, VHS tapes — all were normal and then gone.
Looking ahead 20 years, what’s around us now that you think will completely disappear? Cars as we know them? Physical cash? Plastic credit cards? Traditional universities?
r/accelerate • u/pigeon57434 • 3d ago
let me know if I missed anything
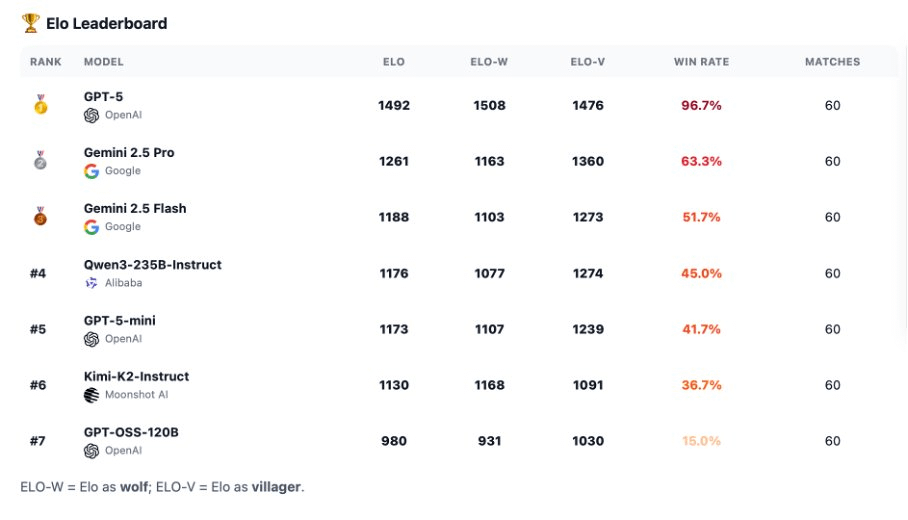{kind=link}
{kind=link}
{kind=link}